Climate Risk Analysis of Sierra Club Press Releases#
Project Overview#
This project aims to analyze Sierra Club press releases to identify and quantify mentions of climate risks, focusing on transition risks and physical risks. We’ll use both traditional (TF-IDF) and modern (BERT) NLP techniques to process and analyze the text data.
Installation#
Before we begin, let’s install the necessary packages for this lab. Run the following cell to install the required libraries:
%pip install nlp4ss
Setup and Data Loading#
We import necessary libraries and initialize the project environment using HyFI.
NLTK data is downloaded for text processing tasks.
The Sierra Club press release data is loaded from a JSONL file into a pandas DataFrame.
from hyfi import HyFI
if HyFI.is_colab():
HyFI.mount_google_drive()
project_root = "/content/drive/MyDrive/nlp4ss"
else:
project_root = "$HOME/workspace/courses/nlp4ss"
h = HyFI.initialize(
project_name="nlp4ss",
project_root=project_root,
logging_level="INFO",
verbose=True,
)
print("Project directory:", h.project.root_dir)
print("Project workspace directory:", h.project.workspace_dir)
/home/yjlee/.venvs/nlp4ss/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
INFO:hyfi.utils.notebooks:Extension autotime not found. Install it first.
INFO:hyfi.joblib.joblib:initialized batcher with <hyfi.joblib.batcher.batcher.Batcher object at 0x7f1b3fe9b2b0>
INFO:hyfi.main.config:HyFi project [nlp4ss] initialized
Project directory: /home/yjlee/workspace/courses/nlp4ss
Project workspace directory: /home/yjlee/workspace/courses/nlp4ss/workspace
import re
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
import gensim.downloader as api
from transformers import BertTokenizer, BertModel
import torch
from sklearn.metrics.pairwise import cosine_similarity
nltk.download("punkt")
nltk.download("punkt_tab")
nltk.download("stopwords")
nltk.download("wordnet")
[nltk_data] Downloading package punkt to /home/yjlee/nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package punkt_tab to /home/yjlee/nltk_data...
[nltk_data] Package punkt_tab is already up-to-date!
[nltk_data] Downloading package stopwords to /home/yjlee/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package wordnet to /home/yjlee/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
True
# Load the data
raw_data_file = h.project.workspace_dir / "data/raw/articles.jsonl"
rdata = h.load_dataset("json", data_files=raw_data_file.as_posix())
df = rdata["train"].to_pandas()
print(df.info())
print("\nSample of the data:")
print(df.head())
# Sample data
df = df.sample(500, random_state=42)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6354 entries, 0 to 6353
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 6354 non-null object
1 timestamp 6354 non-null object
2 url 6354 non-null object
3 page_url 6354 non-null object
4 page 6354 non-null int64
5 content 6354 non-null object
6 uuid 6354 non-null object
dtypes: int64(1), object(6)
memory usage: 347.6+ KB
None
Sample of the data:
title timestamp \
0 Sierra Club Urges Commerce Department to Hold ... April 15, 2024
1 Sierra Club Statement on BOEM Financial Assura... April 15, 2024
2 We Energies Files Third Rate Increase in Three... April 15, 2024
3 MEDIA ADVISORY: Oregon Regulators to Hear Conc... April 12, 2024
4 Advisory: Special Meeting for County Commissio... April 12, 2024
url \
0 https://www.sierraclub.org/press-releases/2024...
1 https://www.sierraclub.org/press-releases/2024...
2 https://www.sierraclub.org/press-releases/2024...
3 https://www.sierraclub.org/press-releases/2024...
4 https://www.sierraclub.org/press-releases/2024...
page_url page \
0 https://www.sierraclub.org/press-releases?_wra... 1
1 https://www.sierraclub.org/press-releases?_wra... 1
2 https://www.sierraclub.org/press-releases?_wra... 1
3 https://www.sierraclub.org/press-releases?_wra... 1
4 https://www.sierraclub.org/press-releases?_wra... 1
content \
0 April 15, 2024\n\n\nContact\nAda Recinos, Depu...
1 April 15, 2024\n\n\nContact\nIan Brickey, ian....
2 April 15, 2024\n\n\nContact\nMegan Wittman, me...
3 April 12, 2024\n\n\nContact\nKim Petty, Sierra...
4 April 12, 2024\n\n\nContact\nLee Ziesche, lee....
uuid
0 9ee69b6c-cd7a-4617-94d2-18951266c182
1 deed5268-32a0-4607-9c0e-e4f565b189f7
2 c0486029-319a-46c8-9622-56bdd61fd9e5
3 3ebc6ab6-15a5-4ccc-953b-593965ae0ad8
4 924abe2c-586d-4087-b4f2-208b731ebb2b
Define Initial Climate Risk Keywords#
We start with two lists of initial keywords: one for transition risks and another for physical risks.
These keywords are based on common terms associated with each type of climate risk.
Bua, G., Kapp, D., Ramella, F., & Rognone, L. (2024). Transition versus physical climate risk pricing in European financial markets: A text-based approach. The European Journal of Finance, 1-35.
# Initial keyword lists
initial_transition_risk_keywords = [
"EJ/YR",
"Radiative Forcing",
"HCFC",
"Ozone",
"Bioenergy",
"Technical Potential",
"GHG Emissions",
"Refrigerant",
"IPCC",
"GHG",
"Ozone Layer",
"Geothermal",
"Pathways",
"Exajoules",
"Biomass",
"Hydropower",
"GigaJoules",
"Photovoltaics",
"Chlorofluorocarbon",
"Heat Pumps",
"Ocean Energies",
"Carbon Dioxide Capture and Storage",
"Mitigation Scenarios",
"Lifecycle",
"USD/kWh",
"Fluid",
"Equivalent CO2",
"Methane",
"Halon",
"Blowing Agent",
"Aerosols",
"Leakage",
"Sustainable Development",
"UNEP",
"Montreal Protocol",
"Anthropogenic",
"Radiative",
"Wind Energy",
"Solar energy",
"Hydrogen",
"UNFCCC",
"Product carbon footprints",
"report safeguarding",
"geological storage",
"direct solar",
"Reservoir",
"IEA",
"anthropogenic",
"adaptation options",
"ecosystems",
"global warming potential",
"ozone-depleting substances",
"GTCO2",
"global warming",
"primary energies",
"ocean",
"atmosphere",
"EQ/YR",
"dioxide capture and storage",
"methane",
"ocean storage",
"equivalent",
"dioxide capture",
"change mitigation",
"teap",
"levels cost",
"energies systems",
"life cycle climate performance",
"mitigation options",
"capacity factors",
"TWH/YR",
"feedstock",
"foam",
"solvent",
"biofuels",
"ozone depletion",
"sustainable development",
"Tco2",
"MTCO2",
"MTCO2 EQ",
"stratospheric",
"climate systems",
"troposphere",
"investment cost",
"human system",
]
initial_physical_risk_keywords = [
"coastal",
"ecosystem services",
"climate models",
"wetlands",
"ipcc",
"adaptation",
"ryosphere",
"ice sheet",
"biodiversity",
"species",
"phytoplankton",
"antarctic",
"climate variables",
"biophysical",
"ghg",
"pathways",
"climate change",
"precipitation",
"anthropogenic",
"coupled model",
"intercomparison projects",
"cyclones",
"climate related",
"ocean",
"streamflow",
"adaptation response",
"change impacts",
"observed change",
"socioeconomic",
"freshwater",
"temperature increase",
"coastal zones",
"sea level",
"phenology",
"future climate",
"upwelling",
"fisheries",
"hazards",
"general circulation models",
"nutrient",
"adaptation",
"permafrost",
"arid",
"reefs",
"water resources",
"terrestrial",
"spatial",
"coral",
"land degradation",
"RCP",
"adaptation planning",
"change climate",
"glaciers",
"salinity",
"hydrological variables",
"sediment",
"tropical cyclones",
"latitudes",
"projected change",
]
def preprocess_text(text):
# Convert to lowercase and remove special characters
text = re.sub(r"[^a-zA-Z\s]", "", text.lower())
# Tokenize
tokens = word_tokenize(text)
# Remove stopwords and short words
stop_words = set(stopwords.words("english"))
tokens = [t for t in tokens if t not in stop_words and len(t) > 3]
# Lemmatize
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(t) for t in tokens]
return " ".join(tokens)
# Preprocess keywords
initial_transition_risk_keywords = [
preprocess_text(keyword) for keyword in initial_transition_risk_keywords
]
initial_physical_risk_keywords = [
preprocess_text(keyword) for keyword in initial_physical_risk_keywords
]
# Remove duplicates
initial_transition_risk_keywords = list(set(initial_transition_risk_keywords))
physicalinitial_physical_risk_keywords_risk_keywords = list(
set(initial_physical_risk_keywords)
)
# Replace space with underscore
initial_transition_risk_keywords = [
keyword.replace(" ", "_")
for keyword in initial_transition_risk_keywords
if len(keyword) > 0
]
initial_physical_risk_keywords = [
keyword.replace(" ", "_")
for keyword in initial_physical_risk_keywords
if len(keyword) > 0
]
print("Number of transition risk keywords:", len(initial_transition_risk_keywords))
print("Transition risk keywords:", initial_transition_risk_keywords)
print("Number of physical risk keywords:", len(initial_physical_risk_keywords))
print("Physical risk keywords:", initial_physical_risk_keywords)
Number of transition risk keywords: 77
Transition risk keywords: ['ozone_layer', 'pathway', 'aerosol', 'direct_solar', 'human_system', 'geothermal', 'report_safeguarding', 'carbon_dioxide_capture_storage', 'sustainable_development', 'hydrogen', 'global_warming_potential', 'lifecycle', 'biofuels', 'anthropogenic', 'unfccc', 'stratospheric', 'fluid', 'solvent', 'capacity_factor', 'foam', 'adaptation_option', 'photovoltaics', 'reservoir', 'exajoules', 'ozone_depletion', 'ocean', 'ejyr', 'radiative', 'heat_pump', 'change_mitigation', 'feedstock', 'gtco', 'investment_cost', 'methane', 'geological_storage', 'mitigation_option', 'hydropower', 'teap', 'hcfc', 'leakage', 'level_cost', 'technical_potential', 'troposphere', 'ecosystem', 'radiative_forcing', 'montreal_protocol', 'halon', 'ocean_energy', 'emission', 'unep', 'life_cycle_climate_performance', 'climate_system', 'ipcc', 'dioxide_capture', 'blowing_agent', 'wind_energy', 'dioxide_capture_storage', 'twhyr', 'ozone', 'atmosphere', 'gigajoules', 'energy_system', 'product_carbon_footprint', 'ocean_storage', 'mtco', 'usdkwh', 'bioenergy', 'global_warming', 'solar_energy', 'refrigerant', 'biomass', 'chlorofluorocarbon', 'primary_energy', 'mitigation_scenario', 'equivalent', 'ozonedepleting_substance', 'eqyr']
Number of physical risk keywords: 57
Physical risk keywords: ['coastal', 'ecosystem_service', 'climate_model', 'wetland', 'ipcc', 'adaptation', 'ryosphere', 'sheet', 'biodiversity', 'specie', 'phytoplankton', 'antarctic', 'climate_variable', 'biophysical', 'pathway', 'climate_change', 'precipitation', 'anthropogenic', 'coupled_model', 'intercomparison_project', 'cyclone', 'climate_related', 'ocean', 'streamflow', 'adaptation_response', 'change_impact', 'observed_change', 'socioeconomic', 'freshwater', 'temperature_increase', 'coastal_zone', 'level', 'phenology', 'future_climate', 'upwelling', 'fishery', 'hazard', 'general_circulation_model', 'nutrient', 'adaptation', 'permafrost', 'arid', 'reef', 'water_resource', 'terrestrial', 'spatial', 'coral', 'land_degradation', 'adaptation_planning', 'change_climate', 'glacier', 'salinity', 'hydrological_variable', 'sediment', 'tropical_cyclone', 'latitude', 'projected_change']
Expand Keywords Using Word Embeddings#
We use pre-trained Word2Vec embeddings to find semantically similar words to our initial keywords.
The
expand_keywordsfunction takes a list of keywords and returns an expanded list of related terms.We combine the original keywords with the expanded ones to create our final keyword lists.
This expansion helps capture a broader range of terms related to climate risks, potentially improving our analysis.
%%time
# Load pre-trained word embeddings
word2vec_model = api.load("word2vec-google-news-300")
def expand_keywords(keywords, model, topn=5):
expanded_keywords = set()
for keyword in keywords:
try:
similar_words = model.most_similar(keyword, topn=topn)
expanded_keywords.update([word.lower() for word, _ in similar_words])
except KeyError:
continue # Skip words not in the vocabulary
return list(expanded_keywords)
# Expand keyword lists
expanded_transition_keywords = expand_keywords(
initial_transition_risk_keywords, word2vec_model
)
expanded_physical_keywords = expand_keywords(
initial_physical_risk_keywords, word2vec_model
)
# Combine original and expanded keywords
transition_risk_keywords = (
initial_transition_risk_keywords + expanded_transition_keywords
)
physical_risk_keywords = initial_physical_risk_keywords + expanded_physical_keywords
# Remove duplicates
transition_risk_keywords = list(set(transition_risk_keywords))
physical_risk_keywords = list(set(physical_risk_keywords))
print("Number of expanded transition risk keywords:", len(transition_risk_keywords))
print("Number of expanded physical risk keywords:", len(physical_risk_keywords))
print("Expanded transition risk keywords:", transition_risk_keywords)
print("Expanded physical risk keywords:", physical_risk_keywords)
INFO:gensim.models.keyedvectors:loading projection weights from /home/yjlee/gensim-data/word2vec-google-news-300/word2vec-google-news-300.gz
INFO:gensim.utils:KeyedVectors lifecycle event {'msg': 'loaded (3000000, 300) matrix of type float32 from /home/yjlee/gensim-data/word2vec-google-news-300/word2vec-google-news-300.gz', 'binary': True, 'encoding': 'utf8', 'datetime': '2024-08-23T12:09:38.654130', 'gensim': '4.3.3', 'python': '3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0]', 'platform': 'Linux-5.15.0-1029-nvidia-x86_64-with-glibc2.35', 'event': 'load_word2vec_format'}
Number of expanded transition risk keywords: 221
Number of expanded physical risk keywords: 201
Expanded transition risk keywords: ['equals', 'pathway', 'aerosol', 'ozone_layer', 'stratospherically', 'astronomic', 'leaks', 'metal_hydride', 'geothermal', 'montreal_protocol', 'dioxide_capture', 'atlantic_ocean', 'seepage', 'aquatic_ecosystem', 'atmopshere', 'supply_chain', 'ozone_concentrations', 'geothermic', 'dioxide_capture_storage', 'lignol_modified', 'petrochemical_feedstock', 'photovoltaics_pv', 'hydrogen', 'solar_energy', 'lifecycle', 'biofuels', 'radiative_forcing', 'polyurethane_foam', 'mtoe', 'direct_solar', 'renewable_fuels', 'hydro', 'manmade_global_warming', 'chlorofluorocarbon_cfc', 'pacific_ocean', 'ozonedepleting_substance', 'anthropogenic', 'unfccc', 'carbon_dioxide', 'ecosytem', 'polariton', 'atmospheric_co2', 'equivilant', 'stratospheric', 'marine_ecosystem', 'equates', 'fluid', 'solvent', 'life_cycle_climate_performance', 'stratospheric_ozone_depletion', 'renewable_feedstocks', 'foam', 'greenhouse_warming', 'lifecycles', 'biorefining', 'photovoltaics', 'cellulosic_ethanol', 'hydrogen_fuel', 'reservoir', 'methane_gas', 'stratospheric_ozone_layer', 'exajoules', 'polaritons', 'pathways', 'ocean', 'dam', 'sustainable_development', 'report_safeguarding', 'refrigerants', 'r###a', 'terawatts', 'ejyr', 'anthropogenic_climate', 'sulfate_aerosol', 'mesosphere', 'r_###a_refrigerant', 'kwh', 'cfcs_chlorofluorocarbons', 'level_cost', 'oceans', 'ocean_energy', 'ozone_depletion', 'radiative', 'cosmic_ray_flux', 'solar_thermal', 'greenhouse_gases', 'woody_biomass', 'foam_insulation', 'solvents', 'hydrogen_powered', '##twh', 'capacity_factor', 'human_system', 'feedstock', 'gtco', 'lifecyle', 'photovoltaic', 'groundwater_aquifer', '##kwh', 'dizzying_heights', 'tropopause', 'methane', 'ormat', 'technical_potential', 'geo_thermal', 'fluids', 'atmospheres', 'emmissions', 'astronomical', 'typing_optical_trackpad', 'gigawatts_gw', 'hydropower_plants', 'hydro_electric', 'greenhouse_gas_emission', 'ecosystems', 'insulation_foam', 'hydropower', 'teap', 'hcfc', 'sugar_cane_bagasse', 'upper_troposphere', 'biomass_feedstock', 'sniffing_glue_lighter', 'solar_cells', 'leakage', 'quadrillion_btus', 'leakages', 'aerosolized', 'forcings', 'extracted_groundnut', 'carbon_emission', 'emissions', 'troposphere', 'ecosystem', 'mitigation_option', 'mitigation_scenario', 'fine_particle_pollution', 'surfactant_replacement_therapies', 'change_mitigation', 'oceanic', 'atmostphere', 'kw_h', 'stratosphere', 'solar_irradiance', 'fluorocarbons', 'bio_fuels', 'adaptation_option', 'wind_energy', 'halon', 'aerosols', 'equivalents', 'ionosphere', 'emission', 'vapor_degreasing', 'unep', 'primary_energy', 'climate_system', 'ozone_smog', 'reservoirs', 'carbon_dioxide_co2', 'dipole_moment', 'geological_storage', 'carbon_dioxide_capture_storage', 'ipcc', 'stratospheric_ozone', 'ozone_depleting_substance', 'bipv', 'ozone_pollution', 'ambience', 'ozone', 'twhyr', 'alternative_fuels', 'atmosphere', 'solar_photovoltaics', 'leak', 'gigajoules', 'investment_cost', 'global_warming_potential', 'signaling_pathway', 'hfc_###a', 'lifecycle_management', 'water_vapor', 'paths', 'pericardial_sac', 'aerosol_spray', 'hydroelectric', 'energy_system', 'biofuel', 'mtco', 'heat_pump', 'earth_ozone_layer', 'chlorofluorocarbons_cfcs', 'climate_change', 'usdkwh', 'ocean_storage', 'path', 'sea', 'dispersive', 'molecular_pathway', 'ambiance', 'global_warming', 'equivilent', 'product_carbon_footprint', 'bioenergy', 'blowing_agent', 'protective_ozone_layer', 'hydro_electric_power', 'hydrogen_fueling', 'insulating_foam', 'refrigerant', 'biomass', 'halons', 'hydrofluorocarbon', 'chlorofluorocarbon', 'ethanol', 'feedstocks', 'equivalent', 'gases', 'kilowatthours', 'co2_emission', 'eqyr']
Expanded physical risk keywords: ['freshwater_wetlands', 'project_budburst', 'pathway', 'hazard', 'costal', 'arowana', 'atlantic_ocean', 'computational_methods', 'danger', 'spatial', 'hydrologic', 'spacial', 'precip', 'hazardous', 'arctic_permafrost', 'coastal', 'adaptations', 'ecosystem_service', 'echelon', 'upwelling', 'radiative_forcing', 'terrestrial', 'salinity', 'adaptation_planning', 'bio_diversity', 'estuaries', 'pangolin', 'terrestial', 'pacific_ocean', 'levels', 'anthropogenic', 'water_resource', 'atmospheric_co2', 'corals', 'tropical_storm', 'wetland', 'spatio_temporal', 'biological_macromolecules', 'species', 'permafrost', 'rainfall', 'educational_attainment', 'latitude_coordinates', 'greenhouse_warming', 'adaptation_response', 'sediments', 'about_musicnotes_musicnotes', 'thawing_permafrost', 'level', 'general_circulation_model', 'pathways', 'terrestrially', 'level.the', 'future_climate', 'ocean', 'freshwater', 'coast', 'climate', 'snowfall', 'melting_permafrost', 'land_degradation', 'corrugated_container', 'nutrient', 'inland', 'phenology', 'temperature_increase', 'anthropogenic_climate', 'salmon_fishery', 'coral_reefs', 'oceans', 'change_impact', 'reef', 'lakes', 'microbial_ecology', 'fisheries', 'observed_change', 'change_climate', 'icecap', 'sheet', 'coastlines', 'biodiversity_conservation', 'dissolved_oxygen_levels', 'specie', 'ryosphere', 'parched', 'cyclone_nargis', 'photoperiodic', 'phytoplankton_bloom', 'pollinator', 'hydrological_variable', 'cyclone', 'climate_variable', 'adaption', 'phosphorus', 'wiggle_room', 'ecosystems', 'antarctica', 'antartic', 'cod_fisheries', 'projected_change', 'streamflows', 'terrestrial_analogue', 'salinities', 'streamflow', 'snowpacks', 'adapation', 'socio_economic', 'sediment', 'recreational_fishery', 'contaminated_sediment', 'upwellings', 'coastline', 'glacier', 'oceanic', 'cycad', 'cyclones', 'critically_endangered', 'socioeconomic_backgrounds', 'coral', 'cyclone_giri', 'siberian_permafrost', 'streamflow_forecasts', 'spitzbergen', 'arid_lands', 'cinematic_adaptation', 'biophysical', 'herring_fishery', 'reefs', 'coral_reef', 'ocean_upwelling', 'adapatation', 'arid', 'phenological', 'sedimentation', 'threshold', 'receding_glaciers', 'ipcc', 'coastal_zone', 'socioeconomic_status', 'adaptation', 'floodplain', 'lattitude', 'freshwater_lakes', 'latitude', 'antarctic', 'climate_related', 'dissolved_oxygen', 'hazards', 'computational_algorithms', 'silt', 'signaling_pathway', 'arid_regions', 'paths', 'uses_perpendicular_lenticular', 'metabolomic', 'terrestrial_transmitters', 'arid_desert', 'spatially', 'tripping_hazard', 'sheets', 'marine_biodiversity', 'phytoplankton', 'nutrients', 'icefield', 'biodiversity', 'semi_arid', 'soil_salinity', 'socioeconomic', 'fishery', 'phytoplankton_blooms', 'plankton', 'climate_change', 'plankton_blooms', 'wetland_habitat', 'precipitation', 'path', 'saltwater', 'leeway', 'climate_model', 'sea', 'fringing_reef', 'molecular_pathway', 'wetlands', 'glaciers', 'global_warming', 'discretion', 'hazzard', 'spatiotemporal', 'freshwater_habitats', 'coupled_model', 'micronutrients', 'tropical_cyclone', 'glacial_ice', 'socioeconomics', 'adélie_penguins', 'topological', 'diatoms', 'nitrogen', 'zooplankton', 'intercomparison_project', 'tropical_depression']
CPU times: user 2min 32s, sys: 1min 48s, total: 4min 21s
Wall time: 35.5 s
Text Preprocessing#
We define a function to preprocess the text, which includes:
Converting to lowercase
Tokenizing the text
Creating both unigrams and bigrams
This preprocessing step is crucial for capturing both single words and two-word phrases in our analysis.
# Preprocess text to include bigrams
def preprocess_text_with_bigrams(text):
# Convert to lowercase and tokenize
tokens = preprocess_text(text).split()
# Create unigrams and bigrams
unigrams = tokens
bigrams = [f"{tokens[i]}_{tokens[i+1]}" for i in range(len(tokens) - 1)]
return unigrams + bigrams
# Update the dataframe with preprocessed text including bigrams
df["processed_content_bigrams"] = (
df["content"].apply(preprocess_text_with_bigrams).apply(" ".join)
)
# Print the updated dataframe
df[["processed_content_bigrams"]].head()
| processed_content_bigrams | |
|---|---|
| 5775 | april contact emily pomilio emilypomiliosierra... |
| 1840 | october contact shiloh hernandez earthjustice ... |
| 4272 | december contact courtney bourgoin courtneybou... |
| 80 | black household face disproportionately high e... |
| 3133 | february contact gabby brown gabbybrownsierrac... |
TF-IDF Analysis#
We use TF-IDF (Term Frequency-Inverse Document Frequency) to analyze the importance of climate risk keywords in each document.
The TF-IDF vectorizer is configured to use our specific climate risk vocabulary.
We calculate separate scores for transition risks and physical risks based on the TF-IDF matrix.
%%time
# TF-IDF Analysis with bigrams
tfidf_vectorizer = TfidfVectorizer(
vocabulary=set(transition_risk_keywords + physical_risk_keywords)
)
tfidf_matrix = tfidf_vectorizer.fit_transform(df["processed_content_bigrams"])
# Calculate risk scores using sum method
df["tfidf_transition_score_sum"] = tfidf_matrix[
:,
[
tfidf_vectorizer.vocabulary_.get(word)
for word in transition_risk_keywords
if word in tfidf_vectorizer.vocabulary_
],
].sum(axis=1)
df["tfidf_physical_score_sum"] = tfidf_matrix[
:,
[
tfidf_vectorizer.vocabulary_.get(word)
for word in physical_risk_keywords
if word in tfidf_vectorizer.vocabulary_
],
].sum(axis=1)
# Calculate risk scores using cosine similarity
transition_risk_keywords_vector = tfidf_vectorizer.transform(transition_risk_keywords)
physical_risk_keywords_vector = tfidf_vectorizer.transform(physical_risk_keywords)
df["tfidf_transition_score_sim"] = df["processed_content_bigrams"].apply(
lambda x: cosine_similarity(
tfidf_vectorizer.transform([x]), transition_risk_keywords_vector
).mean()
)
df["tfidf_physical_score_sim"] = df["processed_content_bigrams"].apply(
lambda x: cosine_similarity(
tfidf_vectorizer.transform([x]), physical_risk_keywords_vector
).mean()
)
# Normalize scores
for col in [
"tfidf_transition_score_sum",
"tfidf_physical_score_sum",
"tfidf_transition_score_sim",
"tfidf_physical_score_sim",
]:
df[col] = (df[col] - df[col].min()) / (df[col].max() - df[col].min())
# Combine scores
df["tfidf_transition_score"] = (
df["tfidf_transition_score_sum"] + df["tfidf_transition_score_sim"]
) / 2
df["tfidf_physical_score"] = (
df["tfidf_physical_score_sum"] + df["tfidf_physical_score_sim"]
) / 2
CPU times: user 801 ms, sys: 651 μs, total: 802 ms
Wall time: 802 ms
# Display results
print("Top 10 articles by TF-IDF physical risk score (combined):")
print(
df[["processed_content_bigrams", "tfidf_physical_score"]]
.sort_values("tfidf_physical_score", ascending=False)
.head(10)
)
print("\nTop 10 articles by TF-IDF transition risk score (combined):")
print(
df[["processed_content_bigrams", "tfidf_transition_score"]]
.sort_values("tfidf_transition_score", ascending=False)
.head(10)
)
# Visualization
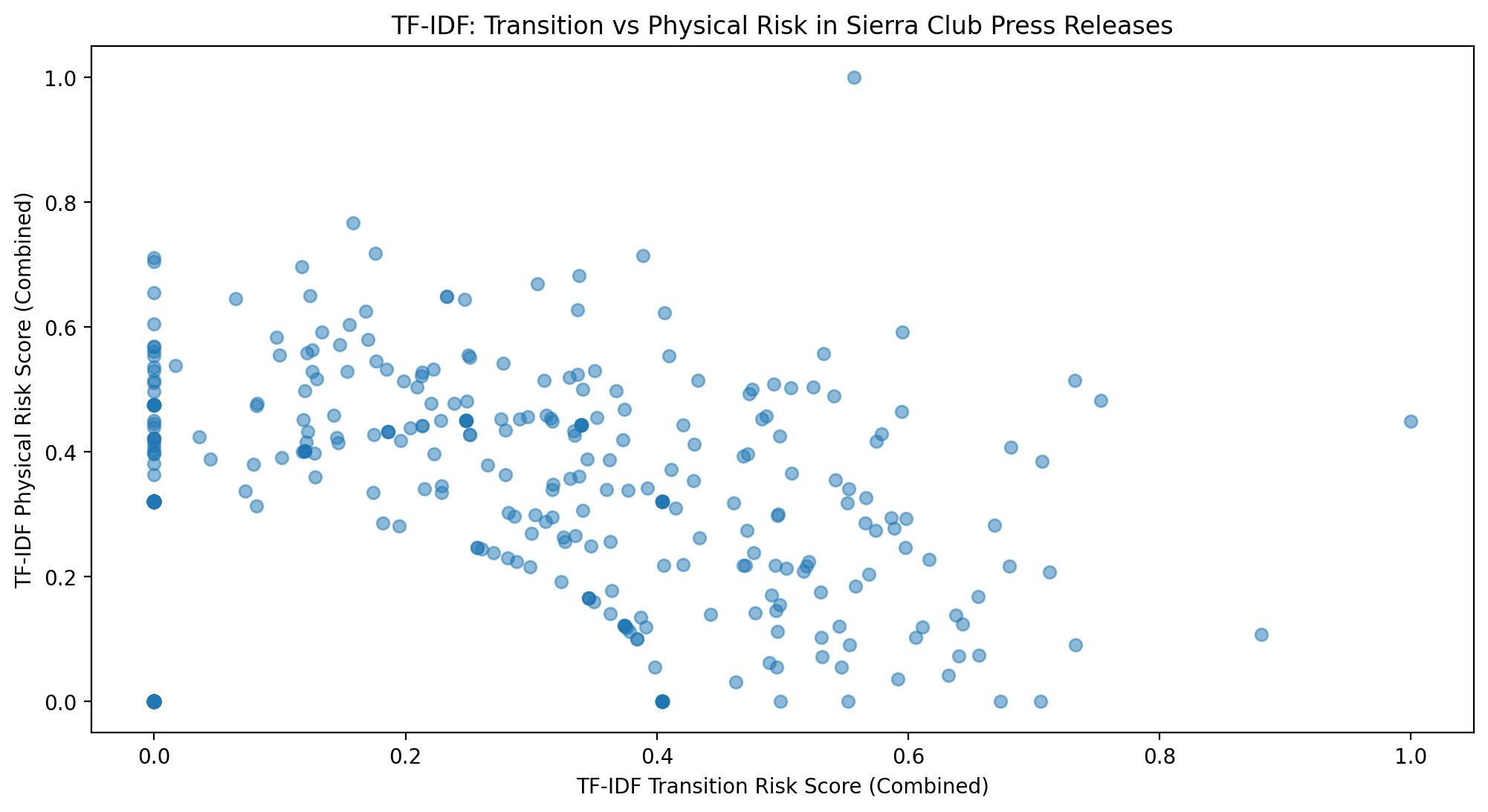
plt.figure(figsize=(12, 6))
plt.scatter(df["tfidf_transition_score"], df["tfidf_physical_score"], alpha=0.5)
plt.xlabel("TF-IDF Transition Risk Score (Combined)")
plt.ylabel("TF-IDF Physical Risk Score (Combined)")
plt.title("TF-IDF: Transition vs Physical Risk in Sierra Club Press Releases")
plt.show()
Top 10 articles by TF-IDF physical risk score (combined):
processed_content_bigrams tfidf_physical_score
3896 government national climate assessment directl... 1.000000
2715 tongass national forest jeopardized push aband... 0.767211
1199 group file petition affidavit louisiana offici... 0.718412
4442 october contact trey pollard treypollardsierra... 0.714806
3494 september contact adam beitman adambeitmansier... 0.711288
3386 october contact gabby brown sierra club gabbyb... 0.705285
2464 enero contacto javier sierra javiersierrasierr... 0.697268
425 september contact larisa manescu larisamanescu... 0.682795
5889 february contact shane levy shanelevysierraclu... 0.669556
4578 august contact ricky junquera rickyjunquerasie... 0.655046
Top 10 articles by TF-IDF transition risk score (combined):
processed_content_bigrams \
393 october contact dominguez amydominguezsierracl...
208 fullyconstructed wind turbine power massachuse...
5925 january contact emily pomilio emilypomiliosier...
4872 unanimous decision norman city council adopts ...
2847 business support bold action energy modernizat...
5058 mountain valley pipeline announces plan expand...
2755 september contact emily pomilio emilypomiliosi...
4050 february contact lauren lantry laurenlantrysie...
4411 wake county becomes county state nationally ad...
3551 august contact cywinski timcywinskisierraclubo...
tfidf_transition_score
393 1.000000
208 0.880798
5925 0.753404
4872 0.732780
2847 0.732336
5058 0.712532
2755 0.706397
4050 0.705275
4411 0.681453
3551 0.680237
BERT-based Analysis#
We use BERT (Bidirectional Encoder Representations from Transformers) for a more context-aware analysis of climate risk mentions.
The
get_bert_embeddingfunction generates embeddings for text using BERT.The
contextual_keyword_importancefunction calculates the importance of keywords in the context of each document, considering both semantic similarity (via BERT embeddings) and keyword frequency.We calculate BERT-based scores for both transition and physical risks.
# Check if GPU is available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# Load pre-trained BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased").to(device)
Using device: cuda
%%time
def get_bert_embedding(text):
inputs = tokenizer(
text, return_tensors="pt", truncation=True, padding=True, max_length=512
)
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
return outputs.last_hidden_state.mean(dim=1).cpu().numpy().flatten()
def contextual_keyword_importance(text, keywords):
# Get BERT embeddings for the full text and keywords
text_embedding = get_bert_embedding(text)
keyword_embeddings = np.array(
[get_bert_embedding(keyword.replace("_", " ")) for keyword in keywords]
)
# Calculate attention scores
attention_scores = cosine_similarity(
text_embedding.reshape(1, -1), keyword_embeddings
).flatten()
# Count keyword occurrences (considering bigrams)
keyword_counts = np.array(
[text.lower().count(keyword.replace("_", " ")) for keyword in keywords]
)
# Combine attention scores and counts
importance_scores = attention_scores * keyword_counts
return importance_scores.sum()
# Calculate BERT-based scores
df["bert_transition_score"] = df["content"].apply(
lambda x: contextual_keyword_importance(x, transition_risk_keywords)
)
df["bert_physical_score"] = df["content"].apply(
lambda x: contextual_keyword_importance(x, physical_risk_keywords)
)
# Normalize scores
for col in ["bert_transition_score", "bert_physical_score"]:
df[col] = (df[col] - df[col].min()) / (df[col].max() - df[col].min())
CPU times: user 45min 13s, sys: 1h 21min 40s, total: 2h 6min 54s
Wall time: 9min 33s
Results Analysis and Visualization#
We display the top 10 articles for each risk type and analysis method.
Scatter plots are created to visualize the relationship between transition and physical risk scores for both TF-IDF and BERT methods.
# Display results
print("Top 10 articles by TF-IDF transition risk score:")
print(
df[["content", "tfidf_transition_score"]]
.sort_values("tfidf_transition_score", ascending=False)
.head(10)
)
print("\nTop 10 articles by TF-IDF physical risk score:")
print(
df[["content", "tfidf_physical_score"]]
.sort_values("tfidf_physical_score", ascending=False)
.head(10)
)
print("\nTop 10 articles by BERT transition risk score:")
print(
df[["content", "bert_transition_score"]]
.sort_values("bert_transition_score", ascending=False)
.head(10)
)
print("\nTop 10 articles by BERT physical risk score:")
print(
df[["content", "bert_physical_score"]]
.sort_values("bert_physical_score", ascending=False)
.head(10)
)
# Visualization
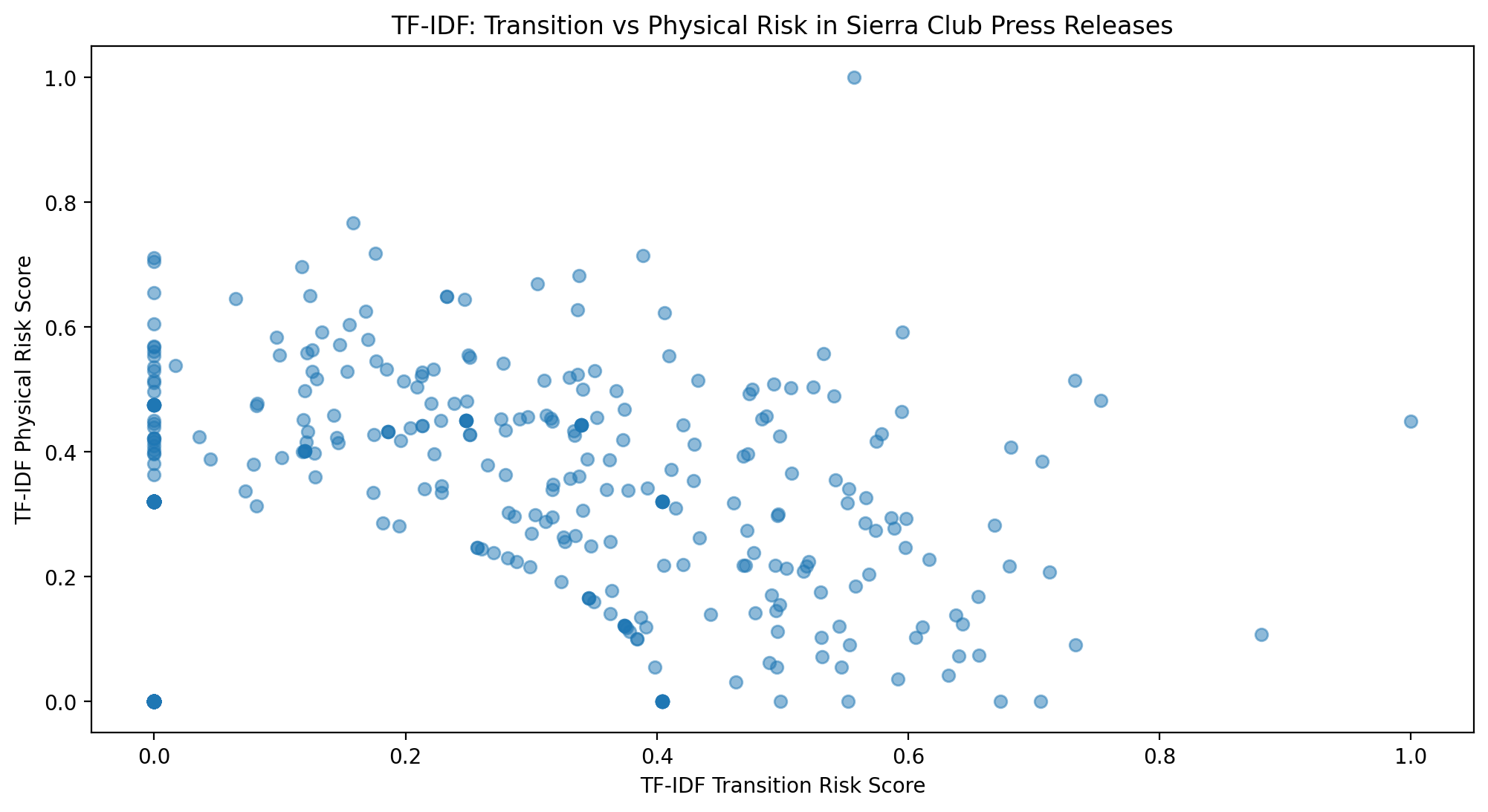
plt.figure(figsize=(12, 6))
plt.scatter(df["tfidf_transition_score"], df["tfidf_physical_score"], alpha=0.5)
plt.xlabel("TF-IDF Transition Risk Score")
plt.ylabel("TF-IDF Physical Risk Score")
plt.title("TF-IDF: Transition vs Physical Risk in Sierra Club Press Releases")
plt.show()
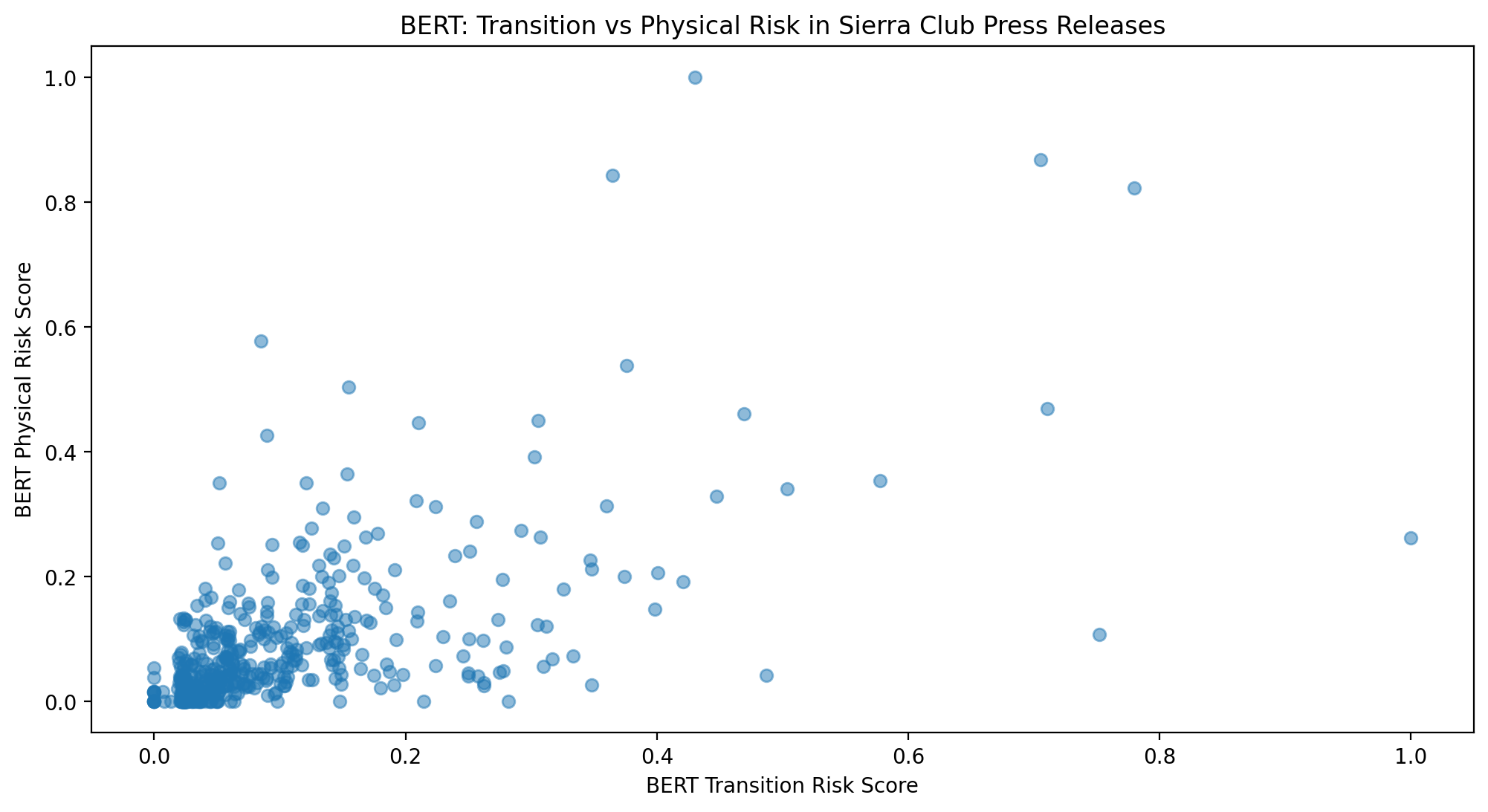
plt.figure(figsize=(12, 6))
plt.scatter(df["bert_transition_score"], df["bert_physical_score"], alpha=0.5)
plt.xlabel("BERT Transition Risk Score")
plt.ylabel("BERT Physical Risk Score")
plt.title("BERT: Transition vs Physical Risk in Sierra Club Press Releases")
plt.show()
Top 10 articles by TF-IDF transition risk score:
content \
393 October 2, 2023\n\n\nContact\nAmy Dominguez, A...
208 When Fully-Constructed, the 62 Wind Turbines W...
5925 January 24, 2017\n\n\nContact\nEmily Pomilio (...
4872 In a unanimous decision, Norman City Council a...
2847 Businesses Support Bold Action in Energy Moder...
5058 Mountain Valley Pipeline Announces Plans to Ex...
2755 September 9, 2020\n\n\nContact\nEmily Pomilio,...
4050 February 26, 2019\n\n\nContact\nLauren Lantry,...
4411 Wake County becomes 3rd county in state, 10th ...
3551 August 29, 2019\n\n\nContact\nTim Cywinski, 54...
tfidf_transition_score
393 1.000000
208 0.880798
5925 0.753404
4872 0.732780
2847 0.732336
5058 0.712532
2755 0.706397
4050 0.705275
4411 0.681453
3551 0.680237
Top 10 articles by TF-IDF physical risk score:
content tfidf_physical_score
3896 The U.S. Government’s National Climate Assessm... 1.000000
2715 Tongass National Forest jeopardized by push to... 0.767211
1199 Groups file petition with affidavit from Louis... 0.718412
4442 October 8, 2018\n\n\nContact\n Trey Pollard tr... 0.714806
3494 September 20, 2019\n\n\nContact\nAdam Beitman,... 0.711288
3386 October 31, 2019\n\n\nContact\nGabby Brown, Si... 0.705285
2464 20 de enero de 2021\n\n\nContacto\nJavier Sier... 0.697268
425 September 20, 2023\n\n\nContact\nLarisa Manesc... 0.682795
5889 February 13, 2017\n\n\nContact\nShane Levy - s... 0.669556
4578 August 27, 2018\n\n\nContact\n Ricky Junquera,... 0.655046
Top 10 articles by BERT transition risk score:
content bert_transition_score
503 New Poll Finds 68% Support EPA Safeguards to R... 1.000000
1533 March 15, 2022\n\n\nContact\nCarolyn Morrisroe... 0.779621
1421 Crucial for severely asthma burdened communiti... 0.751936
5925 January 24, 2017\n\n\nContact\nEmily Pomilio (... 0.710342
3896 The U.S. Government’s National Climate Assessm... 0.705046
1419 April 29, 2022\n\n\nContact\nSamantha Dynowski... 0.577527
5139 Participants call on DEQ to implement strong p... 0.503703
543 Kentucky Wants the EPA to Say it Isn’t\nJune 2... 0.487295
239 December 11, 2023\n\n\nContact\nGrace Nolan, g... 0.469511
472 Energy Department export approval failed to fu... 0.447547
Top 10 articles by BERT physical risk score:
content bert_physical_score
4541 Over 800 global events in 90 countries, includ... 1.000000
3896 The U.S. Government’s National Climate Assessm... 0.868247
1199 Groups file petition with affidavit from Louis... 0.843045
1533 March 15, 2022\n\n\nContact\nCarolyn Morrisroe... 0.823180
1703 December 21, 2021\n\n\nContact\nCourtney Naqui... 0.578368
4420 October 15, 2018\n\n\nContact\nLauren Lantry, ... 0.538403
3544 Morning Consult Poll for the Sierra Club Comes... 0.503922
5925 January 24, 2017\n\n\nContact\nEmily Pomilio (... 0.469790
239 December 11, 2023\n\n\nContact\nGrace Nolan, g... 0.461239
2018 August 11, 2021\n\n\nContact\nAdam Beitman, ad... 0.450095
Time Series Analysis#
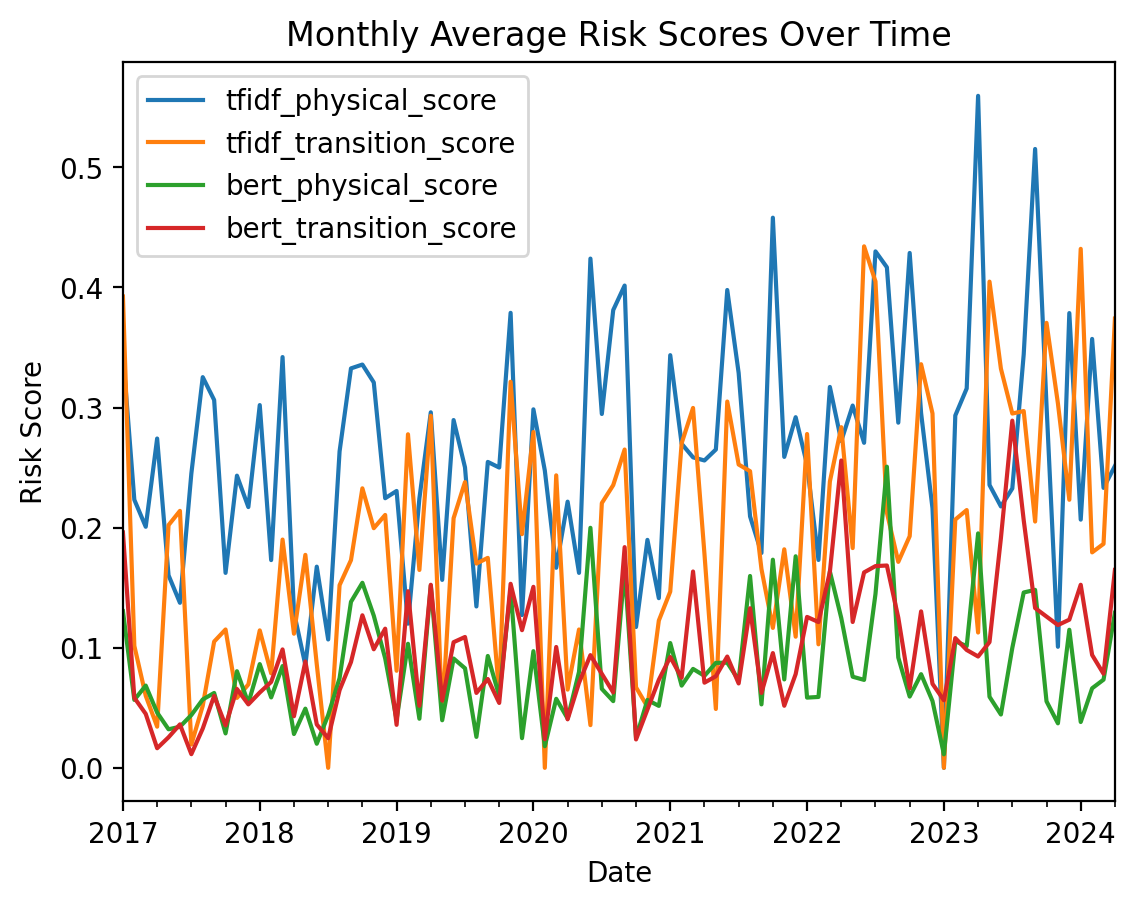
We convert the timestamp to a datetime index and resample the data to monthly averages.
A time series plot is created to show how different risk scores change over time.
# Time series analysis
df["date"] = pd.to_datetime(df["timestamp"], errors="coerce")
df = df.dropna(subset=["date"])
df.set_index("date", inplace=True)
# Monthly average risk scores
monthly_risks = df.resample("M")[
[
"tfidf_physical_score",
"tfidf_transition_score",
"bert_physical_score",
"bert_transition_score",
]
].mean()
# Plot time series
plt.figure(figsize=(14, 7))
monthly_risks.plot()
plt.title("Monthly Average Risk Scores Over Time")
plt.xlabel("Date")
plt.ylabel("Risk Score")
plt.legend(loc="best")
plt.show()
<Figure size 1400x700 with 0 Axes>
Keyword Frequency Analysis#
We analyze the frequency of each keyword in the entire corpus.
The results are displayed for the top 20 most frequent keywords in each category.
Bar plots are created to visualize the top 10 keywords for each risk type.
def analyze_keyword_frequency(keywords, df_column):
keyword_freq = {
keyword: df_column.apply(lambda x: x.count(keyword.replace("_", " "))).sum()
for keyword in keywords
}
return pd.Series(keyword_freq).sort_values(ascending=False)
transition_freq = analyze_keyword_frequency(
transition_risk_keywords, df["processed_content_bigrams"]
)
physical_freq = analyze_keyword_frequency(
physical_risk_keywords, df["processed_content_bigrams"]
)
print("Top 20 most frequent transition risk keywords:")
print(transition_freq.head(20))
print("\nTop 20 most frequent physical risk keywords:")
print(physical_freq.head(20))
# Visualize top keywords
plt.figure(figsize=(12, 6))
transition_freq.head(10).plot(kind="bar")
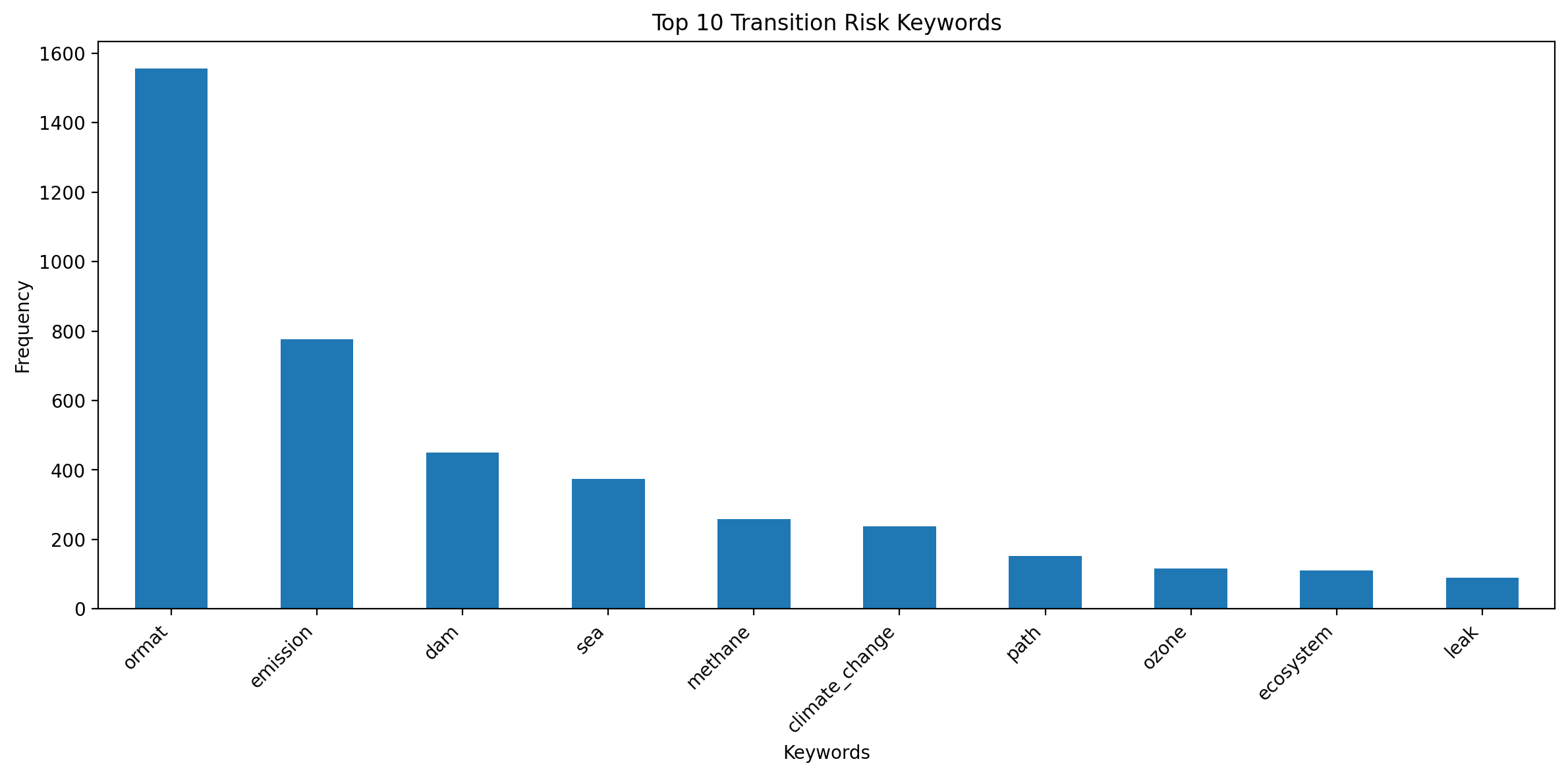
plt.title("Top 10 Transition Risk Keywords")
plt.xlabel("Keywords")
plt.ylabel("Frequency")
plt.xticks(rotation=45, ha="right")
plt.tight_layout()
plt.show()
plt.figure(figsize=(12, 6))
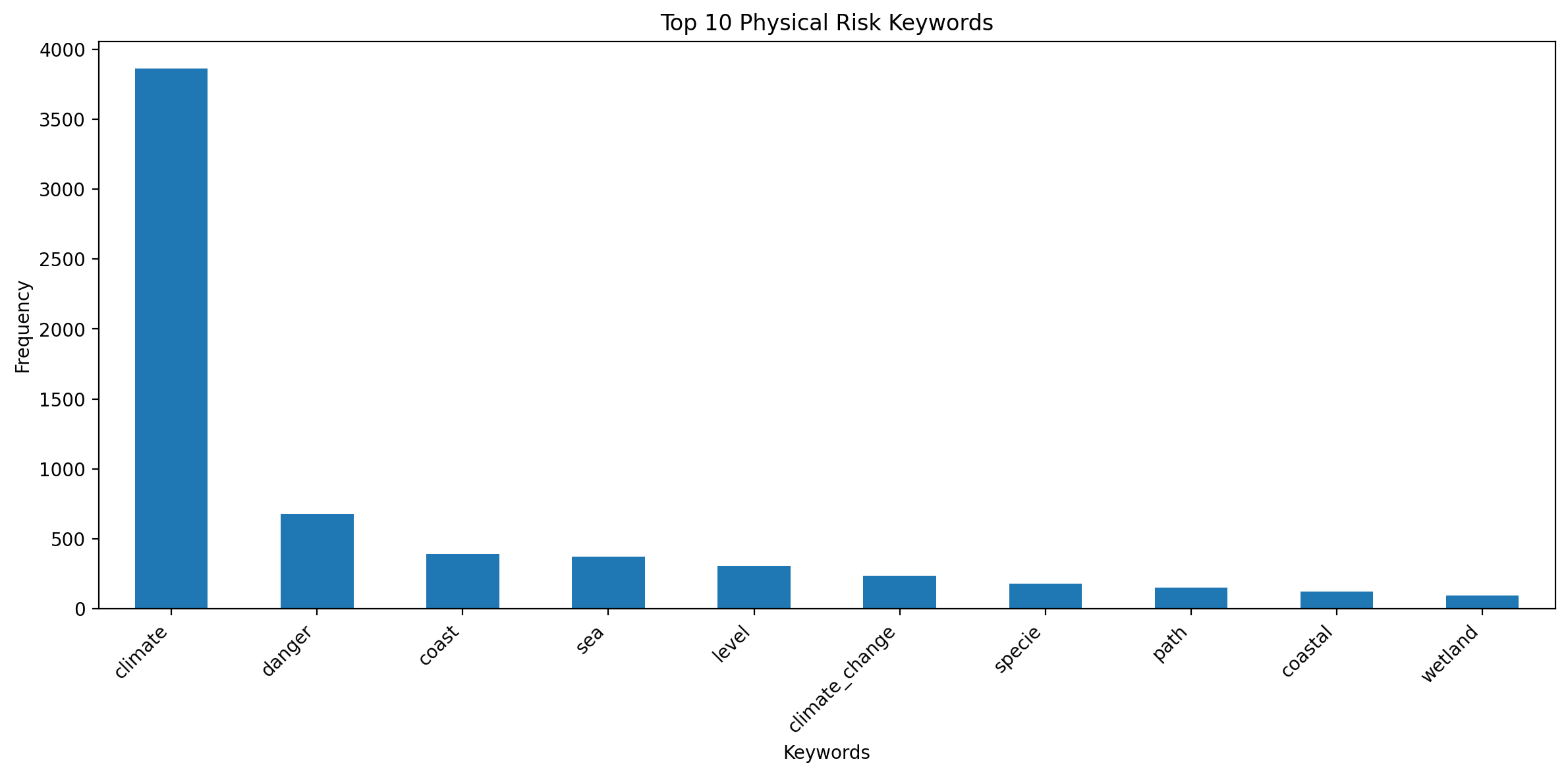
physical_freq.head(10).plot(kind="bar")
plt.title("Top 10 Physical Risk Keywords")
plt.xlabel("Keywords")
plt.ylabel("Frequency")
plt.xticks(rotation=45, ha="right")
plt.tight_layout()
plt.show()
Top 20 most frequent transition risk keywords:
ormat 1557
emission 777
dam 450
sea 375
methane 258
climate_change 237
path 153
ozone 117
ecosystem 111
leak 90
ethanol 65
hydro 51
ocean 42
pathway 33
ipcc 30
carbon_dioxide 22
equivalent 21
hydrogen 21
atmosphere 21
carbon_emission 20
dtype: int64
Top 20 most frequent physical risk keywords:
climate 3864
danger 681
coast 390
sea 375
level 306
climate_change 237
specie 179
path 153
coastal 123
wetland 95
hazard 63
ocean 42
nitrogen 36
pathway 33
hazardous 33
ipcc 30
sheet 21
threshold 18
coastline 15
biodiversity 15
dtype: int64
Conclusion#
This project presents a comprehensive analysis of climate risk discussions in Sierra Club press releases, utilizing both traditional (TF-IDF) and modern (BERT) NLP techniques. By examining transition and physical risks separately, we gain valuable insights into how different aspects of climate change are addressed in environmental communications.
Key findings and implications:
Temporal Trends: The time series analysis reveals evolving patterns in climate risk discourse, potentially reflecting changing priorities or external events influencing the Sierra Club’s messaging.
Risk Type Comparison: By quantifying the emphasis on transition versus physical risks, we can understand which aspects of climate change receive more attention in the organization’s communications.
Keyword Analysis: The frequency analysis of specific climate risk terms provides a granular view of the most prominent topics within each risk category, offering insights into the Sierra Club’s focus areas.
Methodological Comparison: The use of both TF-IDF and BERT-based approaches allows for a nuanced understanding of climate risk mentions, showcasing the strengths and potential complementarity of different NLP techniques.
Keyword Expansion Impact: The incorporation of word embeddings to expand our initial keyword lists demonstrates how semantic relationships can enhance the detection of climate risk discussions, potentially capturing more nuanced or varied terminology.
Limitations and Future Directions:
While keyword expansion increases coverage, it may introduce some noise. Future work could involve refining the expanded keyword list based on domain expertise.
The analysis could be extended to compare results using initial versus expanded keyword lists to quantify the impact of this approach.
Experimenting with different word embedding models or expansion techniques could further optimize the keyword selection process.
Comparative analysis with other environmental organizations’ communications could provide broader context for the Sierra Club’s approach to climate risk discussion.
This project demonstrates the potential of combining traditional and modern NLP techniques to analyze complex environmental communications. By providing a data-driven approach to understanding climate risk discourse, this analysis can inform strategic communication decisions, policy discussions, and further research in environmental studies and climate change communication.